
Gérer la maintenance d’un système de protection foudre sur un seul bâtiment, c’est déjà une affaire de rigueur. Alors, quand on a dix, vingt, ou cent sites, le défi du multi-site maintenance fait que la question n’est plus « est-ce qu’on va y arriver ? », mais « comment préserver l’operational efficiency ? ».
Un plan maintenance multi-sites solide, véritable facility maintenance plan pour les LPS, c’est un mélange simple et exigeant, un référentiel commun, des priorités claires, puis un calendrier réaliste, tenu dans la durée. En mars 2026, avec des exigences QHSE renforcées et des sites souvent sous-traités, on gagne du temps quand tout le monde parle la même langue.
Dans cet article, on pose une méthode pratico-pratique, adaptée aux responsables maintenance, exploitants, facility managers et QHSE, avec une logique calendrier, priorités et suivi via GMAO.
Construire une base commune par site, avant de parler calendrier
Avant de placer une seule date, on doit être d’accord sur « ce qu’on maintient ». Dans le LPS (Lightning Protection System, système de protection contre la foudre), on parle en général de paratonnerres (dont ESE selon les cas), conducteurs, liaisons équipotentielles, prises de terre, parafoudres, et points de contrôle associés.
Le piège dans les multi-location facilities, c’est l’asset inventory hétérogène. Un site appelle un équipement « Parafoudre TGBT », l’autre « SPD armoire », et le troisième n’a même pas de repère. Résultat, on planifie à l’aveugle. On s’en sort en imposant des standardized protocols avec un référentiel unique, identique partout.
Pour cadrer les bases d’une inspection et de ce qui est attendu selon les compliance standards, on peut s’appuyer sur un guide clair comme la méthode complète d’inspection LPS proposée par LPS France, puis décliner la même logique sur tous les sites.
Voici les éléments qu’on collecte systématiquement, site par site, dans le cadre d’un asset management structuré, pour que la planification devienne « mécanique » plutôt que politique :
- Périmètre LPS (bâtiments, zones, extensions, toitures, antennes, ombrières).
- Liste des actifs et repérage (ID unique, photos, localisation).
- Historique (dernière vérification, non-conformités, actions en attente).
- Contraintes d’accès (horaires, habilitations, co-activités, permis).
- Documents (rapports, plans, schémas, études, justificatifs).
À ce stade, on pose aussi des Standard Operating Procedures simples : un actif sans propriétaire, c’est un actif sans maintenance. On attribue donc un pilote par site (chef de site, maintenance locale, prestataire), et on verrouille les circuits de validation.
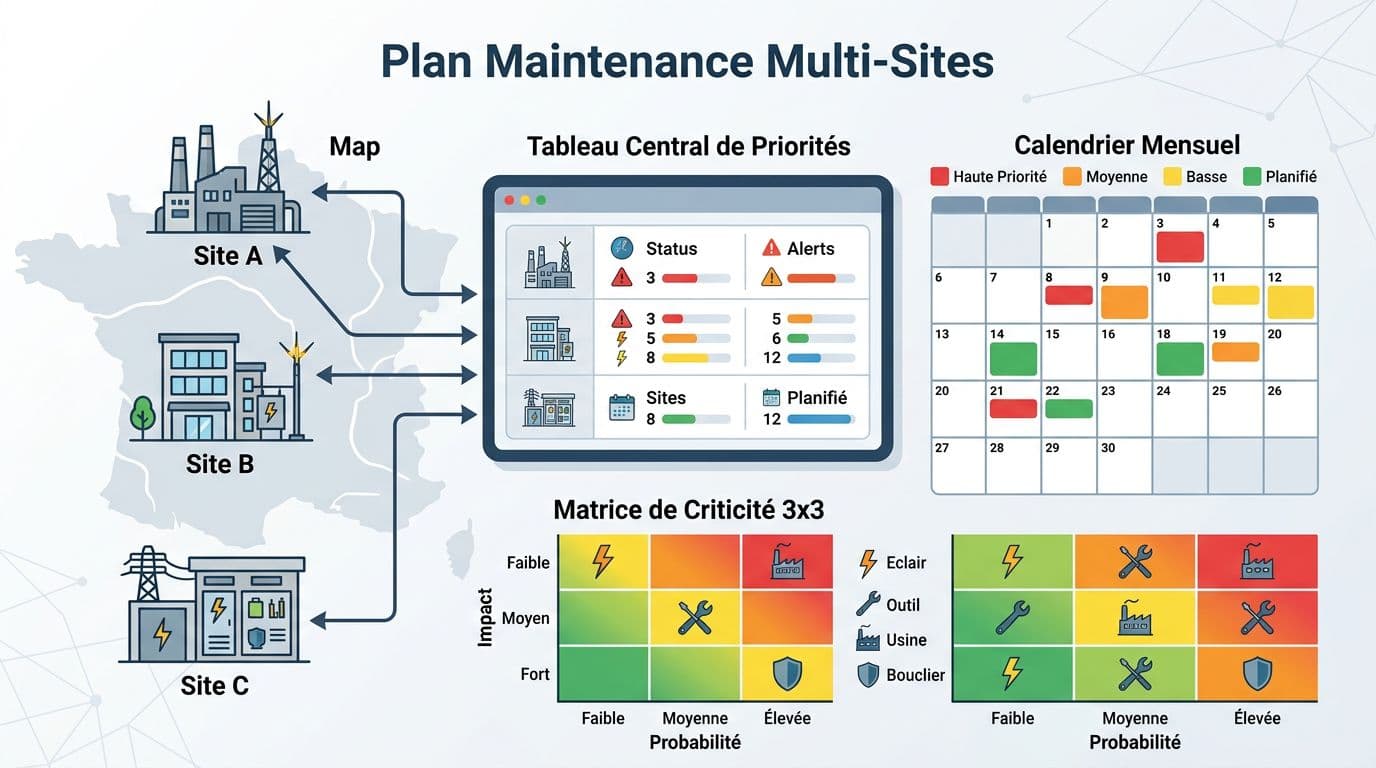
Une fois cette base posée grâce à ces standardized protocols, le calendrier n’est plus un « souhait », il devient la conséquence logique d’un référentiel fiable pour la multi-site maintenance.
Définir des priorités P1 à P4 compréhensibles par maintenance et QHSE
Dans un contexte de multi-site maintenance avec un plan LPS, la priorité n’est pas « ce qui crie le plus fort ». C’est une décision cohérente, répétable, et défendable en audit, au cœur d’une maintenance governance efficace. On a besoin d’un système simple, P1 à P4 par exemple, basé sur deux axes que tout le monde comprend : impact (sécurité, arrêt, conformité) et probabilité (exposition, état, historique). Ce cadre vise notamment la downtime reduction en rendant les arbitrages explicites.
On peut s’inspirer des méthodes de priorisation utilisées en portefeuille, parce qu’elles obligent à rendre les arbitrages explicites, comme dans cette ressource sur la priorisation de projets et critères de décision. L’idée n’est pas de faire compliqué, mais de rendre les choix lisibles.
On formalise ensuite une grille courte, utilisable en réunion hebdo, et compatible GMAO :
| Priorité | Quand on l’utilise | Exemples LPS (courants) | Délai cible |
|---|---|---|---|
| P1 | Reactive maintenance pour danger immédiat, non-conformité majeure, risque élevé | Liaison de terre rompue, parafoudre HS, conducteur coupé | 24 à 72 h |
| P2 | Risque significatif, dégradation avérée | Mesure de terre hors cible interne, fixation dégradée, corrosion avancée | 7 à 30 jours |
| P3 | Preventive maintenance pour conformité à maintenir | Vérification périodique, resserrage, contrôles de continuité | Mois en cours à trimestre |
| P4 | Opportunité, amélioration, standardisation | Mise à jour repérage, ajout de points de test, homogénéisation stock | Trimestre à semestre |
Si on hésite entre deux priorités, on tranche avec une question : « Si ça tombe en panne demain, qui prend le risque, et quel est l’impact concret sur l’activité ? »

Cette priorisation devient notre « langage commun ». Ensuite seulement, on planifie, car on sait quoi décaler, et surtout quoi ne jamais décaler.
Bâtir un calendrier multi-sites tenable pour la multi-site maintenance, puis le faire vivre dans un CMMS software
Un calendrier LPS multi-sites ressemble à un plan de vol. On peut le dessiner très proprement sur un tableur, mais ce qui compte, c’est l’exécution, les retours terrain, et la mise à jour continue.
Pour construire un calendrier robuste de maintenance scheduling, on mélange trois familles de travaux :
- la preventive maintenance obligatoire ou attendue (selon vos référentiels internes et normes applicables),
- les correctifs issus des écarts (P1 et P2 d’abord),
- les actions d’amélioration (P3 et P4, quand la capacité le permet).
On gagne aussi en réalisme en tenant compte de la saison et de la charge. Certains sites ont des fenêtres d’arrêt, d’autres non. Plusieurs équipes se partagent les mêmes prestataires, ce qui favorise la vendor consolidation. Les travaux en toiture demandent météo, accès, permis, parfois nacelle. Planifier, c’est arbitrer avec une bonne resource allocation.
Sur l’optimisation de la planification, les approches académiques rappellent un point utile : on doit gérer les dépendances et les ressources, pas seulement des dates. Pour aller plus loin, on peut lire ce papier sur l’optimisation de calendriers de maintenance (utile pour structurer la réflexion, même si on reste pragmatiques au quotidien).
Voici une séquence simple qu’on applique bien en multi-sites :
- On fixe les rendez-vous non négociables (inspections de preventive maintenance, audits, échéances clients).
- On bloque une capacité mensuelle pour le correctif P1/P2 (sinon, tout explose).
- On regroupe par zones géographiques pour réduire trajets et temps morts.
- On lisse les tâches P3/P4 sur les semaines « creuses ».
- On valide le planning avec exploitation, puis on publie une version figée (et une règle de replanification).
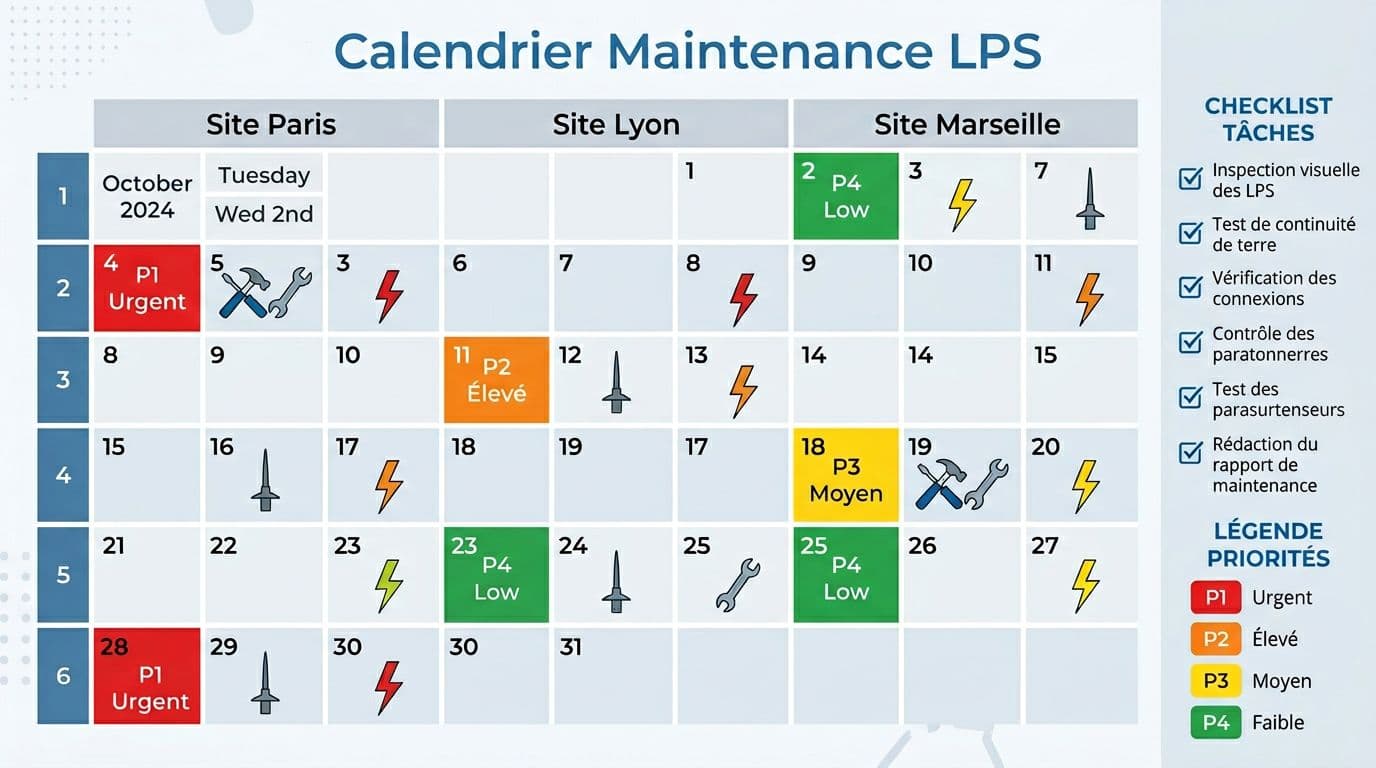
Ensuite, on évite le « planning fantôme » en pilotant dans un CMMS software, avec work orders, statuts, pièces jointes, et preuves terrain via mobile maintenance. Sur les enjeux multi-sites, des retours d’expérience comme ces bonnes pratiques de gestion multi-sites aident à cadrer la standardisation, même si on l’adapte à la foudre.
Dans notre cas, une plateforme dédiée comme LPS Manager sert de colonne vertébrale pour le facility management software : suivi des sites, centralized management documentaire, rapports partageables, et aussi alertes météo et foudre avec real-time data selon les fonctionnalités activées. Pour des retours concrets et des démonstrations, on peut suivre la chaîne YouTube LPS France, pratique pour aligner équipes internes et prestataires sur une même méthode. Cette approche ouvre la porte à la predictive maintenance via IoT sensors ou un digital twin, avec KPI tracking pour mesurer l’équipement uptime.
Au final, un calendrier utile n’est pas « plein », il est tenu via un solide facility maintenance plan.
On reconnaît un bon plan de multi-site maintenance à deux signes simples : les P1 ne traînent pas, et les inspections de preventive maintenance ne se perdent pas. Si on met en place un référentiel commun, une priorisation P1 à P4, puis un calendrier de maintenance scheduling piloté en facility management software et CMMS software avec work orders centralisés, on reprend la main sans alourdir le quotidien. Cela booste l’operational efficiency, la downtime reduction et le cost control dans vos multi-location facilities. La prochaine étape logique, c’est de démarrer par un site pilote pour scaling maintenance, puis d’étendre par vagues en centralized management, en gardant les mêmes règles. Et chez vous, quelle priorité revient le plus souvent, P1 ou P2 ?